
AI Accelerator Chips Overview and Comparison
28/08/2023, hardwarebee
In the evolving era of electronic devices, chip technologies are rising rapidly. One of the most advanced technologies is AI Accelerator Chips. These chips differ in the type of application, and architecture.
Here is below, we discuss what is an AI Accelerator Chip, what companies are making them, and how we can categorize them. At the end we survey 4 AI chips and compare them
What is an AI Accelerator Chip?
An AI accelerator chip, often simply referred to as an AI accelerator, is a specialized hardware component designed to perform artificial intelligence (AI) computations efficiently and quickly. Traditional general-purpose CPUs (central processing units) and GPUs (graphics processing units) are versatile but may not be optimized for the specific demands of AI workloads, which involve heavy parallel processing and matrix calculations commonly found in tasks like deep learning.
AI accelerator chips are tailored to accelerate AI computations, making them significantly faster and more power-efficient compared to using general-purpose processors. These chips are designed to manage the specific operations that are prevalent in AI models, such as matrix multiplications and convolutions. They can drastically speed up AI training and inference tasks, allowing researchers, data scientists, and engineers to develop and deploy AI models more effectively.

Types of AI Accelerator Chips:
- GPUs (Graphics Processing Units): While originally designed for rendering graphics, GPUs are widely used for AI tasks due to their parallel processing capabilities. They can perform multiple calculations simultaneously, making them suitable for the matrix operations commonly found in deep learning.
- TPUs (Tensor Processing Units): Developed by Google, TPUs are specialized chips specifically designed for accelerating Tensor Flow-based AI workloads. They excel in performing tensor operations, which are fundamental to many deep learning algorithms.
- FPGAs (Field-Programmable Gate Arrays): FPGAs are reconfigurable chips that can be programmed to perform specific tasks, including AI computations. They offer more flexibility compared to dedicated AI chips but may require more expertise to program effectively.
- ASICs (Application-Specific Integrated Circuits): ASICs are custom-designed chips optimized for a particular application, in this case, AI computations. They offer high performance and energy efficiency but lack the flexibility of FPGAs.
- Neuromorphic Chips: These chips are designed to mimic the structure and function of biological neural networks. They aim to provide more efficient and biologically inspired AI processing.
- Edge AI Accelerators: These are AI accelerator chips designed for deployment in edge devices like smartphones, cameras, and IoT devices. They are optimized for low power consumption and real-time processing.
What does an AI Accelerator Chip do?
An AI accelerator chip is designed to accelerate and optimize the computation-intensive tasks commonly associated with artificial intelligence (AI) workloads. These chips are built to perform specific mathematical operations that are prevalent in AI models, such as deep learning neural networks. Here’s what an AI accelerator chip does:
- Specialized Operations: AI models, particularly deep learning models, involve operations like matrix multiplications, convolutions, and activation functions. These operations are performed repeatedly during tasks like training and inference. AI accelerator chips are designed to execute these operations efficiently and in parallel, significantly speeding up the overall computation.
- Parallel Processing: One of the key features of AI accelerator chips is their ability to handle massive amounts of parallel processing. They consist of multiple processing units that can perform operations simultaneously, which is crucial for dealing with the vast amounts of data and complex calculations in AI tasks.
- Optimized Hardware Architecture: Traditional CPUs and GPUs are versatile but might not be optimized for AI workloads. AI accelerator chips are engineered with hardware architectures that are specifically tailored to the types of calculations prevalent in AI models. This optimization leads to faster execution times and reduced power consumption compared to using general-purpose processors.
- Energy Efficiency: AI accelerator chips are designed to perform computations with high energy efficiency. AI tasks, especially large-scale deep learning, can be extremely power-hungry. By focusing on the specific computations needed for AI and minimizing unnecessary overhead, these chips can perform calculations with better energy efficiency.
- Large-Scale Data Processing: Many AI tasks involve processing large datasets, which can be time-consuming on traditional processors. AI accelerator chips can handle data processing in a more streamlined manner, reducing the time required to train AI models or perform inference on new data.
- Real-time Processing: In certain applications, such as autonomous vehicles or real-time image recognition, quick decision-making is essential. AI accelerator chips are designed to process data rapidly, enabling real-time responses to changing inputs.
- Optimized for Specific Frameworks: Some AI accelerator chips are optimized for specific deep learning frameworks, such as TensorFlow or PyTorch. This optimization ensures seamless integration and high performance when running models built using these frameworks.
- Deployment Flexibility: AI accelerator chips can be used in various deployment scenarios, including cloud data centers and edge devices. This flexibility allows AI models to be trained and executed efficiently across different environments.
How AI Accelerator Chips Categorized?
AI accelerator chips can be categorized based on several factors, including their architecture, design principles, intended applications, and performance characteristics. Here are some common ways AI accelerator chips are categorized:
- Architecture:
- GPU (Graphics Processing Unit): GPUs are widely used for AI acceleration due to their parallel processing capabilities. They are suitable for tasks like deep learning and image processing.
- TPU (Tensor Processing Unit): TPUs are Google’s custom-designed chips optimized for TensorFlow-based workloads, particularly neural network inference and training.
- FPGA (Field-Programmable Gate Array): FPGAs are reconfigurable chips that can be programmed to perform specific tasks, including AI computations. They offer flexibility but may require more expertise to program.
- ASIC (Application-Specific Integrated Circuit): ASICs are custom-designed chips built specifically for AI computations. They offer high performance and energy efficiency for targeted tasks.
- Neuromorphic Chips: These chips aim to mimic the structure and function of biological neural networks. They are designed for specialized AI applications that require brain-inspired processing.
- Workload and Application:
- Training Accelerators: These chips are optimized for training deep learning models, which involve complex calculations and large datasets.
- Inference Accelerators: These chips are designed to execute trained models on new data quickly, making them suitable for real-time applications like image recognition in cameras or voice assistants in smartphones.
- Edge Accelerators: These chips are designed for deployment in edge devices with limited power and computational resources, such as IoT devices and wearables.
- Framework Compatibility:
- Framework-Specific Accelerators: Some chips are optimized to work seamlessly with specific deep learning frameworks, like TensorFlow, PyTorch, or Caffe. This ensures high performance and efficient execution of models built using these frameworks.
- Power Efficiency:
- High-Performance Accelerators: These chips prioritize maximum processing power and are often used in data centers for large-scale training tasks.
- Low-Power Accelerators: These chips are optimized for energy efficiency and suitable for edge devices and other applications where power consumption is a concern.
- Network Topology:
- Spatial Architectures: These accelerators use a traditional grid-like array of processing units, suitable for tasks with regular data patterns.
- Systolic Arrays: These accelerators use a specialized array of processing units and memory, designed to perform matrix multiplications efficiently.
- Vendor-Specific Categories:
- Various companies might have their own categories or brands for their AI accelerator chips. For example, NVIDIA’s GPUs, Google’s TPUs, and Intel’s FPGAs are well-known vendor-specific offerings.
- Hybrid Approaches:
- Some chips combine multiple types of processing units (e.g., CPUs, GPUs, AI-specific units) to provide a balance between general-purpose computing and AI acceleration.
Remember that the categorization of AI accelerator chips is not always rigid, as technological advancements can lead to new chip designs and categories. The choice of which accelerator to use depends on factors like the specific AI workload, performance requirements, power constraints, and available resources.
Which Companies Make AI accelerator Chips?
To meet the rising demand for effective and high-performance AI processing, several businesses create and produce AI accelerator chips. Leading businesses in this industry include:
- NVIDIA: NVIDIA is a market leader in GPU technology and is credited with being the first to use GPUs to accelerate AI. For AI jobs, a lot of people use their CUDA platform and several GPU models, like the NVIDIA GeForce, Quadro, and Tesla series.
- Google: Known as the Tensor Processing Unit (TPU), Google has created its own AI accelerator hardware. TPUs are used to speed up AI workloads on Google Cloud and are created exclusively for Google’s TensorFlow framework.
- Intel: Intel offers a range of AI accelerator solutions, including FPGAs (such as the Intel FPGA) that can be programmed for AI tasks, as well as AI-focused processors like the Intel Nervana Neural Network Processor (NNP) series.
- AMD: AMD’s GPUs, like the Radeon Instinct series, are utilized for AI workloads alongside their traditional use for graphics. AMD has also been working on AI-specific solutions to compete in this market.
- Graphcore: Graphcore has developed the Intelligence Processing Unit (IPU), a specialized chip designed from the ground up for AI and machine learning tasks. It focuses on delivering high parallelism and efficiency.
- Qualcomm: Qualcomm designs AI accelerator chips for mobile and edge devices. Their AI Engine and Hexagon DSPs are used in many smartphones and IoT devices to accelerate AI tasks.
- Huawei: Huawei’s Ascend AI processors, such as the Ascend series, are designed to provide high-performance AI acceleration for various applications, including cloud computing and edge devices.
- Apple: Apple has incorporated AI accelerator chips into its devices, including the Neural Engine found in recent iPhones and iPads. These chips enhance AI-related tasks like image recognition and natural language processing.
- Xilinx: Xilinx is a major FPGA manufacturer that provides chips for AI acceleration through their adaptable computing platforms. Their Alveo accelerator cards are used in data centers for AI workloads.
- Cerebras Systems: Cerebras has developed the CS-1, a chip designed for deep learning tasks. It boasts one of the largest single chips ever made, containing numerous processing units.
- Microsoft: While not primarily an AI chip manufacturer, Microsoft has been working on Project Brainwave, an architecture that uses FPGAs for AI acceleration on their Azure cloud platform.
- Wave Computing: Wave Computing offers AI systems built on their custom-designed AI chips, which include dataflow processors optimized for AI workloads.
Making an AI chips is a Complex Task
Designing and manufacturing AI accelerator chips is a highly complex process that involves various technical, engineering, and design challenges. Here are some reasons why creating AI chips is complex:
- Hardware Architecture Design: Designing an efficient hardware architecture for AI processing requires a deep understanding of AI algorithms, parallel processing techniques, and memory hierarchies. Engineers need to decide on the types of processing units, memory organization, interconnects, and other architectural details that will optimize performance for specific AI workloads.
- Algorithm Optimization: AI chips are often tailored for specific AI frameworks and algorithms. Optimizing the chip’s architecture to accelerate these algorithms while maintaining accuracy can be challenging. Achieving a good balance between hardware efficiency and algorithmic accuracy is crucial.
- Customization: Different AI workloads have varying computational requirements. Designing a chip that can be customized or configured to handle different types of AI computations efficiently adds complexity to the design process.
- Parallel Processing: AI tasks heavily rely on parallel processing to handle large amounts of data. Designing the chip to efficiently perform parallel operations and manage data flow between processing units is a complex task.
- Memory Hierarchy: Memory access patterns can significantly impact performance. Designing an effective memory hierarchy that minimizes data movement bottlenecks and maximizes data reuse is challenging.
- Power Efficiency: AI chips need to balance high performance with low power consumption. Achieving energy efficiency while delivering the necessary processing power requires careful design choices.
- Software-Hardware Co-Design: AI chips must be compatible with software frameworks and tools used by developers. Coordinating the development of hardware and software components is crucial to ensure smooth integration and optimal performance.
- Manufacturing Challenges: The process of manufacturing chips involves nanoscale fabrication techniques. Ensuring that the chip’s design translates accurately into a physical product requires expertise in semiconductor manufacturing.
- Testing and Verification: Validating the functionality and performance of AI chips is a complex process. Engineers need to verify that the chip operates as intended, handles different types of AI workloads, and doesn’t introduce errors.
- Evolving Standards: The field of AI is rapidly evolving, with new algorithms, frameworks, and techniques emerging frequently. Designing AI chips that remain relevant and adaptable to changing AI landscape is challenging.
- Time-to-Market Pressure: The AI industry is competitive, and companies often aim to release products quickly to capture market share. Balancing the need for speed with the complexities of chip design can be a significant challenge.
Due to these complexities, chip design companies invest heavily in research, development, simulation, testing, and validation processes. They often collaborate with experts in AI algorithms and software to ensure that the resulting chip is capable of efficiently accelerating AI workloads.

Comparing AI Accelerator Chips:
In this section, we are going to compare some AI Accelerator chips from different manufactures.
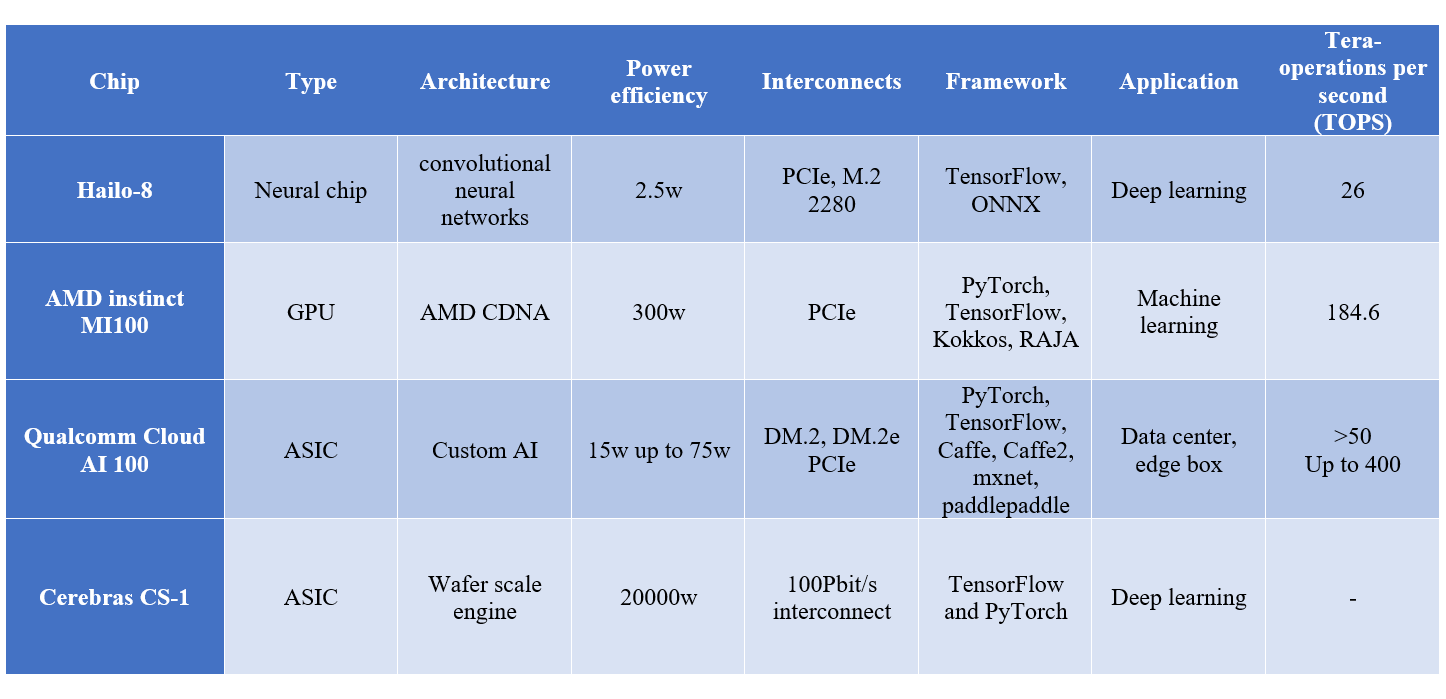
1-Hailo-8:
TEL AVIV, August 3, 2023 – Hailo, the pioneering chipmaker of edge artificial intelligence (AI) processors, today announced it has expanded its groundbreaking Hailo-8™ AI accelerator offering following hundreds of successful deployments in customer programs and products. The new high-performance Hailo-8 Century PCIe card line offers up to 208 Tera Operations per Second (TOPS) for most demanding applications, and the Hailo-8L makes advanced AI processing available for entry-level applications. Both product lines are offered at a competitive price compared to the respective category leaders.[3]
The Hailo-8 AI accelerator chip is a product developed by Hailo, an AI chip startup company. The Hailo-8 chip is designed to provide high-performance AI acceleration for edge devices, enabling real-time processing of AI workloads directly on the device without relying on cloud servers.

Here are some key features and aspects of the Hailo-8 AI accelerator chip:
- Purpose: The Hailo-8 chip is designed to accelerate AI inference tasks, which involve running trained AI models on new data to make predictions or decisions. It is tailored for edge computing applications, where low latency and energy efficiency are crucial.
- Architecture: The chip features a unique architecture optimized for processing deep learning and neural network workloads. It is designed to efficiently handle the types of operations commonly found in convolutional neural networks (CNNs), which are widely used for image and video processing tasks.
- Efficiency: The Hailo-8 chip is engineered to provide high performance while consuming minimal power. This efficiency is essential for edge devices where battery life and heat dissipation are significant considerations.
- Real-Time Processing: The chip’s low-latency capabilities make it suitable for real-time applications like object detection, facial recognition, and autonomous vehicles.
- Custom Hardware Design: Hailo designed the chip from scratch to meet the specific requirements of AI inference. This custom design allows for the optimization of both hardware and software components for maximum efficiency.
- Flexibility: The Hailo-8 chip is designed to be flexible, and capable of supporting various AI models and neural network architectures. This versatility enables it to cater to a wide range of AI applications.
- Industry Applications: The Hailo-8 chip can be used in various industries, including automotive, smart cameras, robotics, drones, and more, where AI-driven real-time processing is essential.
- Software Support: Hailo provides software tools and development kits to help developers integrate and optimize their AI models for the Hailo-8 chip. This simplifies the process of deploying AI-powered solutions.
2- AMD instinct MI100:
The AMD Instinct MI100 is a high-performance AI accelerator card designed for data center and high-performance computing (HPC) applications. It’s part of AMD’s Instinct series of accelerators, which are specifically tailored for AI, machine learning, and other compute-intensive workloads. Here are some key details about the AMD Instinct MI100:
- GPU Architecture: The AMD Instinct MI100 is based on the AMD CDNA (Compute DNA) architecture, which is designed to provide high levels of performance and energy efficiency for data-centric workloads like AI and HPC.
- Compute Power: The MI100 features a high number of computer units, which are responsible for performing the actual calculations in parallel. It offers significant computational power to accelerate AI training and inference tasks.
- Matrix Operations: The architecture of the MI100 is optimized for matrix operations and other calculations commonly found in deep learning neural networks, making it suitable for AI workloads.
- Memory Configuration: The MI100 features a substantial amount of high-bandwidth memory (HBM2) to accommodate the large datasets used in AI and HPC applications. Fast memory access is crucial for performance optimization.
- Heterogeneous System Architecture (HSA): The MI100 supports AMD’s Heterogeneous System Architecture, which allows CPUs and GPUs to work together more efficiently by sharing memory and tasks. This can lead to better performance for certain types of workloads.
- ROCm Ecosystem: AMD’s ROCm (Radeon Open Compute) platform provides the software ecosystem for MI100 and other AMD GPUs. It includes libraries, frameworks, and development tools that enable efficient programming, optimization, and execution of AI and HPC workloads.
- Double Precision Performance: The MI100, being designed for HPC tasks as well, provides strong double-precision performance, making it suitable for scientific simulations and calculations that require high precision.
- Interconnects: The MI100 supports high-speed interconnects like PCIe 4.0, which allow for fast data transfer between the accelerator and the host system.
- Energy Efficiency: The CDNA architecture is designed with energy efficiency in mind, aiming to provide high computing performance while keeping power consumption manageable.

3- Qualcomm Cloud AI 100:
The Qualcomm Cloud AI 100 is a high-performance AI accelerator designed for data centers and cloud computing environments. It was developed by Qualcomm Technologies, Inc., a prominent semiconductor, and telecommunications company known for its mobile chipsets and other technologies. The Qualcomm Cloud AI 100 is part of Qualcomm’s efforts to provide AI solutions for various applications, including machine learning and artificial intelligence.
Here are some key details about the Qualcomm Cloud AI 100:
- Purpose: The Qualcomm Cloud AI 100 is designed to accelerate AI workloads in cloud environments. It targets data centers and cloud service providers that require efficient AI processing capabilities for tasks like machine learning inference, natural language processing, computer vision, and more.
- Architecture: The Qualcomm Cloud AI 100 is built around a custom AI accelerator architecture designed to efficiently handle AI computations. The architecture is optimized for high throughput and low latency, making it suitable for real-time and high-performance AI applications.
- Performance: The AI accelerator is designed to deliver high levels of performance for AI workloads. It is optimized for tasks that involve matrix multiplications, convolutions, and other operations commonly found in deep learning and neural networks.
- Energy Efficiency: Energy efficiency is a crucial consideration for data centers. The Qualcomm Cloud AI 100 is engineered to offer high performance while minimizing power consumption, helping data centers achieve better energy efficiency.
- Compatibility: The accelerator is designed to work with various AI frameworks and software libraries, making it adaptable to different AI applications and development environments.
- Scalability: Cloud data centers often require scalable solutions. The Qualcomm Cloud AI 100 is designed to be scalable, allowing data centers to deploy multiple accelerators to meet their AI processing needs.
- Edge-to-Cloud AI: While the primary focus is on cloud environments, Qualcomm also emphasizes the potential for extending AI processing from the cloud to edge devices, enabling more diverse AI applications.
- Integration: The Qualcomm Cloud AI 100 can be integrated into data center servers and systems, allowing cloud service providers to offer AI services to their customers.
4- Cerebras CS-1:
The Cerebras Systems CS-1 is an innovative AI computing solution developed by Cerebras Systems, a company focused on creating high-performance AI accelerators for deep learning and artificial intelligence applications. The CS-1 is designed to address the computational demands of training and running large neural networks, enabling faster and more efficient AI model development.
Key features and aspects of the Cerebras Systems CS-1 include:
- Wafer Scale Engine (WSE): The CS-1 incorporates the Wafer Scale Engine, a single chip that is much larger than traditional GPUs and other AI accelerators. The WSE integrates thousands of processing cores, memory blocks, and communication pathways, which allows it to manage massively parallel processing and significantly reduce data movement bottlenecks.
- Unprecedented Size: The CS-1’s chip is so large that it is comparable in size to an entire silicon wafer, hence the name “Wafer Scale Engine.” This expansive size provides a unique advantage in reducing the time it takes to move data between processing units, which can be a significant bottleneck in deep learning tasks.
- Performance: The CS-1’s architecture is optimized for deep learning tasks, making it well-suited for training large-scale neural networks. Its extensive computing resources and memory capacity contribute to faster training times and improved model accuracy.
- Memory Capacity: The CS-1 chip includes an ample amount of on-chip memory, which helps store and manage the large amounts of data and parameters needed for training complex models. This minimizes the need to access external memory, improving overall performance.
- Communication Infrastructure: The CS-1’s interconnects enable efficient communication between processing cores, ensuring that data can be shared and processed without delays.
- Energy Efficiency: Despite its large size and high performance, the CS-1 is designed with energy efficiency in mind. This is essential for data center environments, where minimizing power consumption is a priority.
- Software Compatibility: Cerebras Systems provides a software stack that enables developers to program and optimize their AI models for the CS-1 architecture. This includes integration with popular deep-learning frameworks and tools.
- Applications: The CS-1 is targeted at industries and research areas that require substantial AI computational power, such as scientific research, drug discovery, financial modeling, and more.
Conclusion:
In the evolving landscape of AI hardware solutions, the Cerebras Systems CS-1, Qualcomm Cloud AI 100, AMD Instinct MI100, and Hailo-8 AI accelerator chip represent diverse approaches to addressing the increasing demands of AI workloads. Each accelerator caters to different application scenarios, architectural designs, and performance priorities.
The Cerebras Systems CS-1 stands out for its groundbreaking Wafer Scale Engine (WSE) architecture. Its massive chip size and thousands of processing cores enable unparalleled parallelism and reduced data movement, making it a compelling choice for training large neural networks and data-intensive simulations. However, the CS-1’s specialization for extreme scale deployments might limit its accessibility to select use cases.
The Qualcomm Cloud AI 100 focuses on delivering robust AI acceleration for cloud data centers. Its architecture is designed for high throughput and low latency, optimizing it for real-time inference and high-performance cloud AI applications. Qualcomm Cloud AI 100’s compatibility with various AI frameworks and software environments positions it as a versatile option for cloud service providers and data centers.
The AMD Instinct MI100, powered by the CDNA architecture, emphasizes a balance between AI and HPC workloads. Its impressive double-precision performance and support for large datasets make it well-suited for scientific simulations and high-precision AI tasks. AMD’s focus on energy efficiency and compatibility with the ROCm ecosystem adds to its appeal for data centers seeking power-efficient AI acceleration.
The Hailo-8 AI accelerator chip is designed for edge devices, aiming to bring real-time AI processing to IoT devices and embedded systems. Its efficiency, specialized architecture for matrix operations, and ability to manage a variety of AI tasks make it a valuable component for enabling AI at the edge. However, its scope might limit its application to edge computing scenarios.
In conclusion, these AI accelerator solutions highlight the diverse strategies adopted by manufacturers to meet the demands of modern AI workloads. The Cerebras Systems CS-1 and Qualcomm Cloud AI 100 excel in their respective data center and cloud environments, with distinctive architectures optimized for parallelism and real-time processing. The AMD Instinct MI100 bridges the gap between AI and HPC, emphasizing performance and precision, while the Hailo-8 AI accelerator chip targets edge computing with its efficiency and versatility. The choice among these accelerators depends on factors such as workload requirements, deployment scenarios, and architectural preferences, demonstrating the complexity and innovation inherent in the AI hardware landscape.
[1] https://up-shop.org/default/hailo-m2-key.html
[2] https://memryx.com/technology/
[3] https://hailo.ai/hailo-8l-entry-level-ai-accelerator-announcement/






